In ELT workflow the raw source tables are first loaded into a data lake, which is later transformed into a more suitable data model in the data warehouse for reporting. The transformation process can be time consuming or expensive for large batch ELT or streaming ETL for various reasons, for examples:
- Streaming events that require the transformation to run frequently.
- Large tables that require full comparison to find deleted records.
- Tables that do not have created or modified timestamp columns to support change data capture.
Some big data query engines, like Facebook’s Presto are available which can quickly compare massive amounts of data. They however either require managing dedicated servers to run big data engines or pay the premium for services like Amazon Athena.
In such scenarios, Snowflake stream can be a fantastic tool for change data capture (CDC) without any additional overhead. It can be used to run transformations only for the rows changed from a defined point, without comparing full tables or the need to maintain dedicated servers or special big data tools.
Snowflake stream does not store any data. When a stream is created to a source table, it creates an offset for that table and adds two hidden columns to the source table. Any time a row is inserted, updated or deleted, those two rows keep track of the metadata. We can query the stream any time to find changed data since the time offset was created. When a DML operation runs on that streams, the offset moves to the most recent state.
Let us create a table called employee to look at an example. The table has 3 columns: id, name and city. We will also add 10 initial rows into the table.
-- create source table
create table employee(
id int,
name text,
city text
);
-- add inital data
insert into employee values
(1, 'Steve Austin', 'Austin'), (2, 'Hulk Hogan', 'New York'),
(3, 'Brock Lesnar', 'San Jose'), (4, 'Mick Foley', 'Los Angeles'),
(5, 'Shawn Michaels', 'Montana'), (6, 'Bill Goldberg', 'Vermont'),
(7, 'Jeff Hardy', 'Chapell Hill'), (8, 'AJ Styles', 'Riverside'),
(9, 'Scott Hall', 'Mexico City'), (10, 'Dustin Rhodes', 'Mississippi');Now we create a stream that tracks this table:
create stream employee_stream on table employee;We can see the current state of the source table and the tracking stream (initally empty):
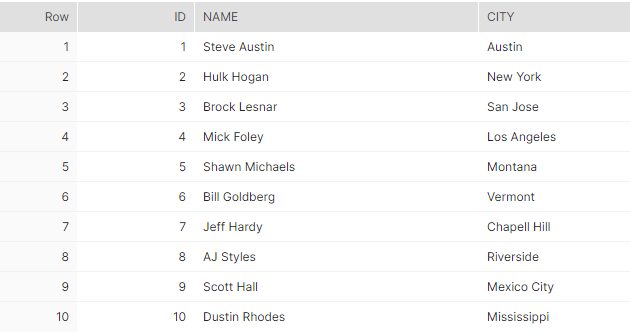

Suppose our target is to create a dimension model from this source table, that also keeps track of historical records. We can use Kimball’s Type 2 slowly changing dimension (SCD) model. Here each row has an effective start timestamp & end timestamp, and a flag that tells if the row is current. Any time a row in the source table is updated or deleted, an end timestamp is added to that row on the target table and marked as inactive. Then the new information from the update is added as a new record.
Because we will use Snowflake to track change data capture (CDC), we first need to create the target dimension table and also add the existing rows as a base load.
-- create target table
create sequence employee_skey_sequence;
create table dim_employee (
employee_skey number primary key default employee_skey_sequence.nextval,
name text,
city text,
effective_date_start datetime,
effective_date_end datetime,
is_current boolean,
id int
);
-- base load
insert into dim_employee (name, city, effective_date_start, is_current, id)
select name, city, current_timestamp, true, id
from employee;We can now query the target table and see its current status.
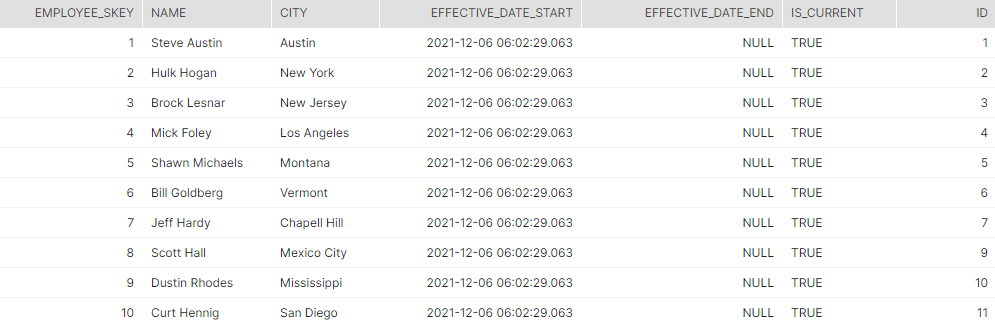
Now, let us simulate some changes on the source table. Such changes may come from batch ELT, from Snowflake’s continous data integration service Snowpipe or from Snowflake connector for Kafka, consuming streaming events from Apache Kafka.
We will add a new row (id = 11), delete an existing row (id = 8) and update an existing row (id = 3).
insert into employee values (11, 'Curt Hennig', 'San Diego');
delete from employee where id = 8;
update employee set city = 'New Jersey' where id = 3;Now let us look at the source table and the corresponding tracking stream.
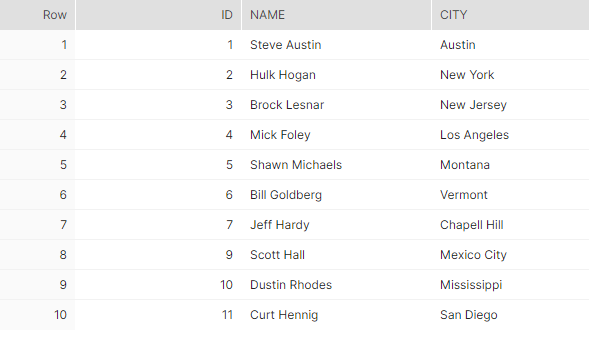

At the stream, we have 4 rows: one row for the delete (id = 8), one row for the insert (id = 11) and 2 rows for the update (id = 3), as the update operation is stored as a two step process: a delete followed by an insert.
We also see 3 additional columns: METADATA$ACTION, METADATA$ISUPDATE and METADATA$ROW_ID. METADATA$ACTION can only have INSERT or DELETE as value. METADATA$ISUPDATE column tells if a delete/insert happened due to an update operation. METADATA$ROW_ID can be used to track changes for a particular row, but we won’t use it for this example.
Now let us write a stored procedure in Snowflake that will consider these changes from the stream and reflect into the target dimension table. Inside the stored procedure, we will use the merge command and base it on the employee id column. When matched, it would mark the existing row as expired by setting the effective_date_end and making the is_current flag false. When not matched, it knows the row does not exist at the target and would insert it.
However, there is one more condition we need to add. For id = 3 (update operation), we get two rows, one for the delete and one for insert. For the DELETE row, we would want the merge condition to MATCH so that it is marked as inactive, but for the INSERT row, we would want the merge condition to NOT MATCH, so that the updated values gets inserted as a new row. We can achieve it by considering METADATA$ACTION as an additional condition.
-- stored procedure to apply changes to the target table
create or replace procedure employee_tranformation()
returns text
language javascript
as
$$
var sqlText = `
merge into dim_employee t
using (
select *
from employee_stream
) s
on t.id = s.id and METADATA$ACTION = 'DELETE'
when matched then
update set
effective_date_end = current_timestamp,
is_current = false
when not matched then
insert (name, city, effective_date_start, is_current, id)
values (s.name, s.city, current_timestamp, true, s.id)
`;
snowflake.execute({sqlText: sqlText});
return 'success';
$$;We can now call this as below and see the result in target table:
call employee_tranformation();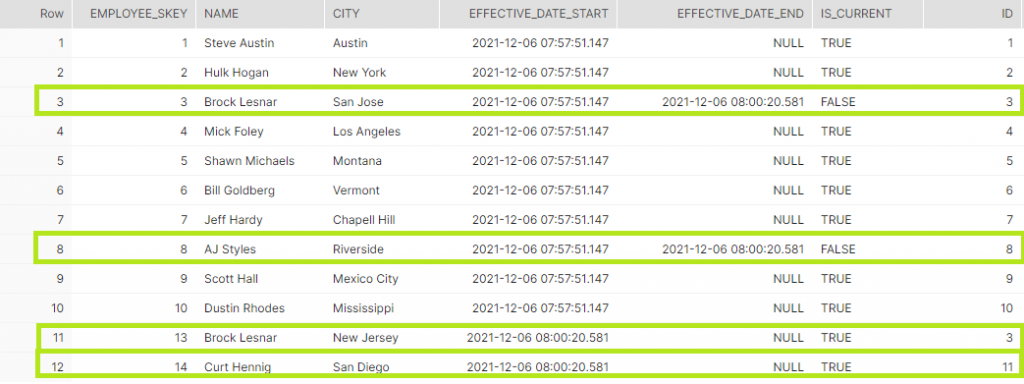
The result shows all the changes in the source have been correctly captured in the target. The main point to focus here is that it did not compare the source table (10 rows) with the target table to determine the insert/update/delete. It used the stream which captured the changed data (4 rows). This may not appear much, but imagine if the source had 1 billion rows and only 100 of them changed. It is in those scenarios where the power of the Snowflake stream would shine.
Finally, we could add this process to run on schedule as a Snowflake task or from an external scheduler, like a trigger in Azure data factory. That would fully automate the continuous ELT process.
Thanks for reading. Let me know if you have any thoughts, experiences to share.
Be First to Comment