PostgreSQL is one of the most popular and feature rich open source relational database. It supports different types of encodings, e.g. ‘SQL_ASCII’, ‘UTF8’, ‘LATIN1’, ‘EUC_KR’ etc. Joel Spolsky has a must read article about unicode and character encoding, but basically character encoding is a mapping between a set of bytes and their corresponding characters. Without knowing the correct encoding of a text, it is not possible to encode or decode from it correctly. For example, UTF-8 is the most common encodding that can store all unicode characters, and may use 1 to 4 bytes to denote a code point.
Even though UTF-8 is an obvious choice when creating a new database in PostgreSQL, it was not fully supported before PostgreSQL 8.1 and was not adopted right away by everyone. So there are still a lot of old PostgreSQL database with SQL_ASCII encoding. Contrary to how it may sound (SQL_ASCII encoding will only support ascii characters), SQL_ASCII actually does not have any encoding convention. According to the official documentation, “...this setting is not so much a declaration that a specific encoding is in use, as a declaration of ignorance about the encoding.“. That means you are totally free to store any character from any encoding and the database will happily accept and store that character. You will only notice the issue when the front-end will try to display the character, assuming it is UTF-8 encoded, and fail miserably, or when you finally decide to migrate from SQL_ASCII to UTF-8 encoding in the database.
Let us observe the issue. We will first create a database with SQL_ASCII encoding and create a test schema and table. We will then store some test rows that include an English word, a French word, a Korean word, an Arabic word and a Bengali word.
-- create a database with SQL_ASCII encoding
create database pg_sql_ascii_db
with encoding 'SQL_ASCII'
lc_ctype 'C'
lc_collate 'C'
template template0
owner etl;
-- create a schema
create schema if not exists raw;
-- create a table to load some test data
create table if not exists raw.account(
account_id bigserial,
account_name text);
-- insert some rows with mixed encoding
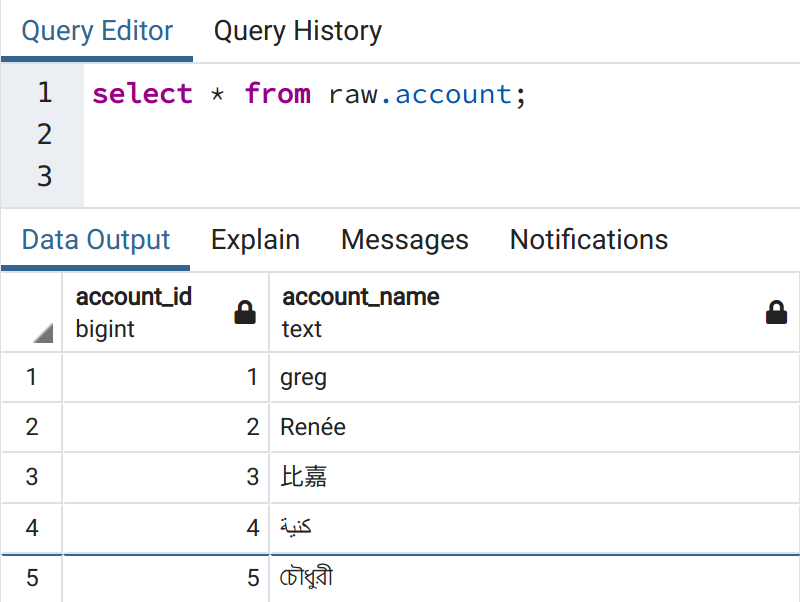
insert into raw.account (account_name) values ('greg'), ('Renée'), ('比嘉'), ('كنية'), ('চৌধুরী');And if we query the database, everything looks correct.
We can add a function in PostgreSQL that will check for us if a table has non-ascii characters, and indeed it shows us that this table has.
drop function if exists public.search_nonscii_characters(text,text);
create function public.search_nonscii_characters(sch_name text, tbl_name text)
returns table(_sch_name text, _tbl_name text, _col_name text, _col_content text)
as $$
declare
_stmnt text;
begin
create temp table temp_non_ascii_content (
_sch_name text,
_tbl_name text,
_col_name text,
_col_content text);
for _col_name in (select
column_name
from
information_schema.columns
where
table_schema = sch_name and
table_name = tbl_name and
data_type in ('character', 'character varying', 'text')
) loop
_stmnt = 'select '|| _col_name ||'::text from '|| sch_name || '.' || tbl_name ||' where '|| _col_name ||' ~ ''[^[:ascii:]]''';
for _col_content in execute (_stmnt) loop
insert into temp_non_ascii_content values (sch_name, tbl_name, _col_name, _col_content);
end loop;
end loop;
return query select * from temp_non_ascii_content;
end;
$$ language plpgsql;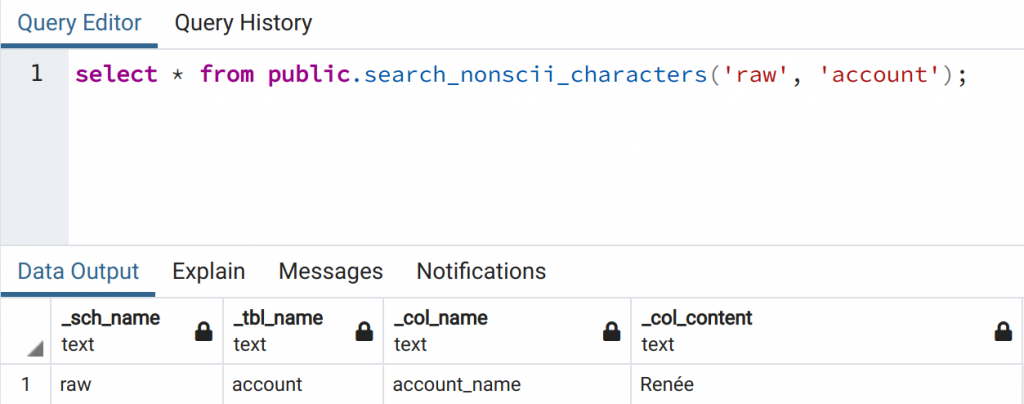
Now, let us try to migrate this table to an UTF-8 encoded database. For that, we will create another test database, with the same schema and table.
-- create a databaes with UTF-8 encoding
create database pg_utf8_db
with encoding 'UTF8'
lc_ctype 'en_US.UTF-8'
lc_collate 'en_US.UTF-8'
template template0
owner etl;
-- create a schema
create schema if not exists raw;
-- create a table to load some test data
create table if not exists raw.account(
account_id bigserial,
account_name text);Now we can use psql command to dump the table from SQL_ASCII encoded database into a CSV file, like below:
psql -h localhost -p 5432 -U etl -d pg_sql_ascii_db -c "\copy raw.account to '~/IdeaProjects/postgresql-encoding-converter/csv/raw.account.csv' delimiter ',' csv header encoding 'SQL_ASCII';"Then we can try to import this CSV into the newly created UTF-8 database.
psql -h localhost -p 5432 -U etl -d pg_utf8_db -c "\copy raw.account from '~/IdeaProjects/postgresql-encoding-converter/csv/raw.account.csv' delimiter ',' csv header encoding 'UTF8';"
Damn. “ERROR: invalid byte sequence for encoding “UTF8″: 0xe9 0x65”. It assumes that the file is encoded as UTF-8, but then fails to load the mystery character that is not encoded as UTF-8.
Solution
If we open the dumped file in an editor like VS Code, we will see that the editor will complain about the encoding, and show a funny character on line 3.
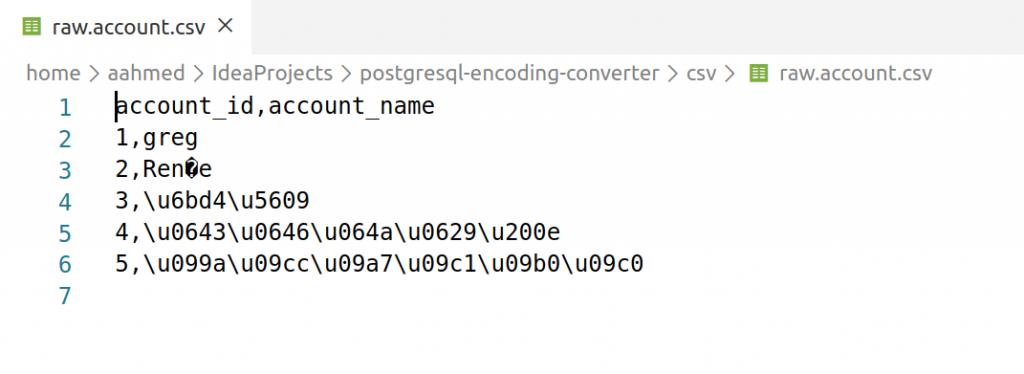
So, an option is to fix this exported file before trying to load into our target database. Here, I have written a Python program that just does that. It takes a list of tables to convert in the config file ‘config.yaml’. It then dumps the table into CSV format from the source database, converts the file into valid utf-8 encoding with Python codecs error handlers, which can also be configured in the ‘config.yaml’ file. The set pre-configured option is ‘backslashreplace’, but you can play with the other options, like ‘ignore’, ‘replace’ etc. that basically says what to do when an unrecognized character is encountered. It can also (optionally) create the target table in the destination database (if not exist already) and upload the data into the target table.
Here is how the program looks like when run and the data in the destination table in the target database with UTF-8 encoding.
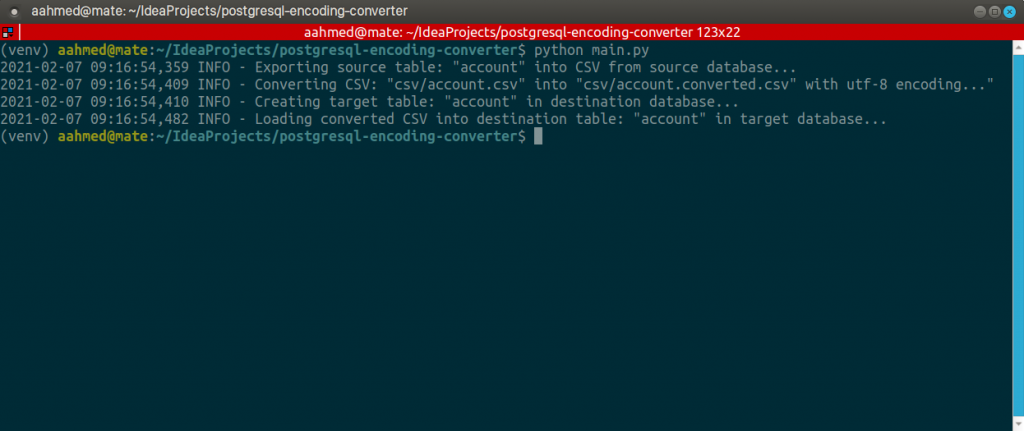
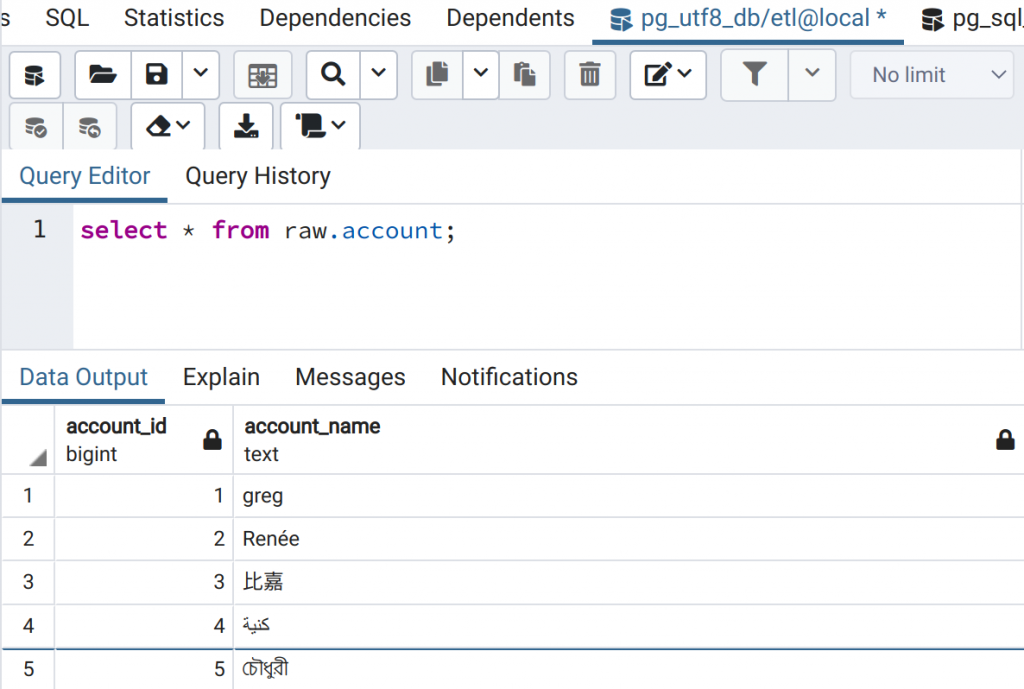
As we can see, the CSV has been converted successfully and the final data looks correct. The source code of the program can be found here.
Great article! Definitely a problem I’ve run into many times when working with Postgres.
Thanks Doug!