As data engineers, we have to collect data from different types of sources and often have to come up with custom data pipelines and ETL tools to move data from one system to another in order to consolidate into a single data warehouse. The sources can be conventional relational databases, NoSQL databases or message bus like Kafka. The type of the load can be full base load or only change data capture. The destination can be another relational database or a columnar database like Amazon Redshift. Each of these types play a crucial part deciding the shape of the data pipeline.
While building custom data pipeline provides a lot of flexibility and granular control, sometimes it is convenient if there is an off-the-shelf tool that can move data from one system to another with pre-built building blocks. StreamSets Data Collector is one such open source tool. In this post, I will look to install it on an Ubuntu based system and create a simple data pipeline to move data from a MySQL database into PostgreSQL (which is actually fairly common, as PostgreSQL excels for data analytics). I will follow up with my initial impressions for the ease of use, functionality and available documentation.
Installation
StreamSets has fair documentation about the installation process. To summarize, the process includes downloading the tar file and extract to a local folder, create four empty folders to set them for configuration, data, log and resources, and finally run the StreamSets program. Upon successful run, it serves the application at localhost on port 18630.
On top of the documented process, a few additional things were required to successfully run on an Ubuntu system.
– Installing Java 8 (if it is not already installed): By default, Ubuntu installs Java 11. StreamSets at the moment only supports Java 8. To install Java 8 and add JAVA_HOME to the path, it requires:
sudo apt install openjdk-8-jdk
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH– Increasing open file limit: Ubuntu comes with a default 1024 as open file limit. StreamSets requires the number to be at least 32768. To increase, it requires to add the two lines below in ‘/etc/security/limits.conf’.
* soft nofile 32768
* hard nofile 32768Followed by adding the following line to ‘/etc/pam.d/common-session*’ files:
session required pam_limits.soThen it just requires to logout and login for the changes to take effect.
Installing External Libraries
StreamSets comes with with a set of drivers for connectors, but there are some that are not included for licensing reason. One such case is the MySQL JDBC driver. The process to install external libraries is documented well, where the MySQL driver can be found from the official page. For this tutorial, I used “mysql-connector-java-5.1.48-bin.jar”. StreamSets already comes with the drivers to connect to PostgreSQL.
Creating the First Pipeline
Three important building blocks in StreamSets are called: Origins, Processors and Destinations. Origins and Destinations are similar in concept: a set of connectors to connect to common resources like relational databases e.g. MySQL, PostgreSQL, SQL Server, Oracle; NoSQL databases like Redis or MongoDB; Amazon S3, gRPC, Kafka etc. to name a few. The processors are a list of blocks that helps to transform the data, for example to drop or rename certain columns, flatten a JSON, convert data types etc.
In this example, I am using a publicly available MySQL database as the origin. The database is called Rfam, which according to the documentation a “collection of non-coding RNA families represented by manually curated sequence alignments, consensus secondary structures, and predicted homologues.” As the destination, I would be using a locally installed PostgreSQL database.
Here is what I want the pipeline to do:
1. Track and continuously load incremental changes from a table in MySQL. In this example, I picked a table named ‘genome’.
2. Automatically select only a few selected columns and remove the rest.
3. Automatically convert incompatible data-types.
4. Automatically create the destination table and required columns in PostgreSQL, with proper data types.
Here is how the pipeline looks like:

MySQL (JDBC Query Consumer)
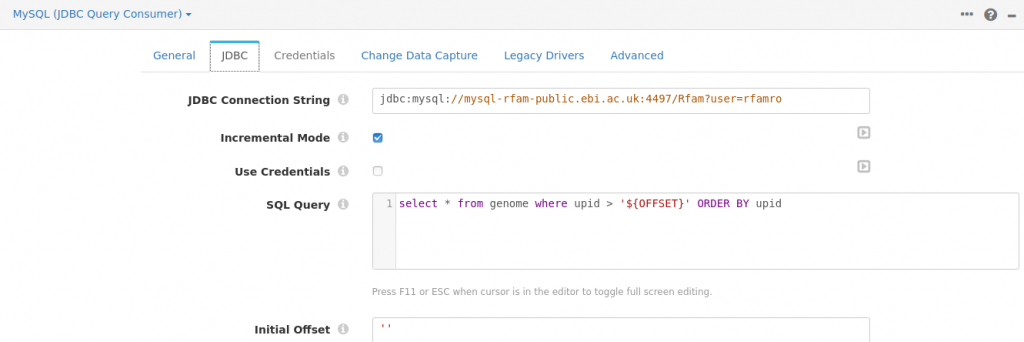
Setting up the MySQL consumer was quite straightforward. Because the publicly available database did not have a password, I had to remove checkbox to use credentials, and pass the username in the JDBC connection string. Here is a screenshot of the configuration:
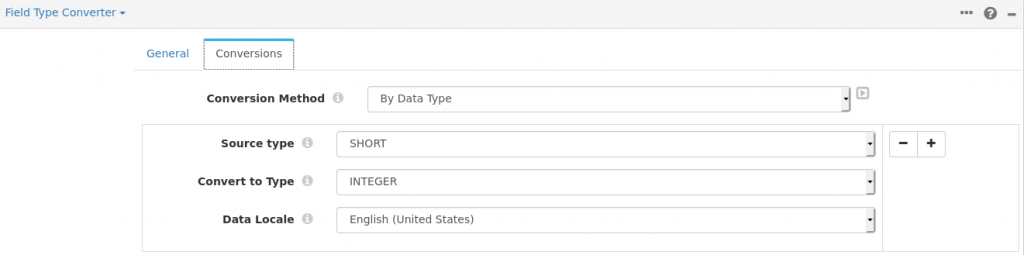
Field Type Converter
The only conversion I required to make was to change the MySQL data type tinyint to integer, as the destination PostgreSQL does not have a short integer data type.
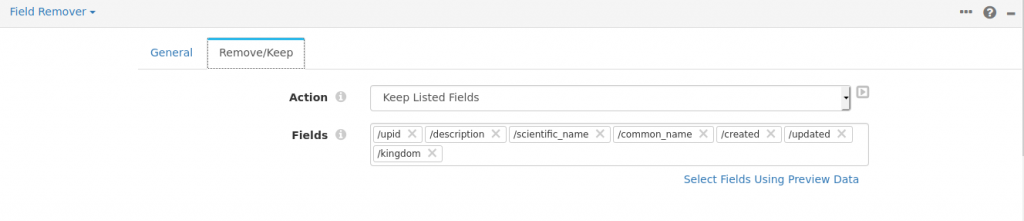
Field Remover
This processor is used to remove the unwanted fields. StreamSets quite conveniently provides a preview option, from where you can visually see and select a list of fields to either keep or remove. Very nice!
PostgreSQL Metadata
This processor is used generate the destination table and required columns. Although the documentation says it is able to create the destination table, in reality I found a validation error if the table did not exist already. I had to create a dummy table with a single column, and only then it was able to add the additional columns. To be fair, they do mention this is still in beta, so hopefully this will be fixed when it goes to production.
PostgreSQL (JDBC Producer)
This again was extremely easy to setup and only required the connection settings.
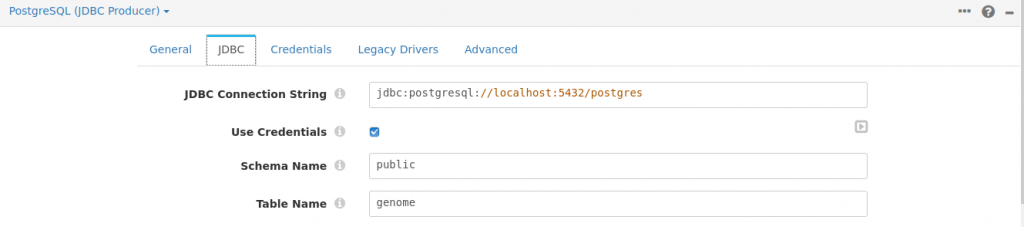
Running the Pipeline
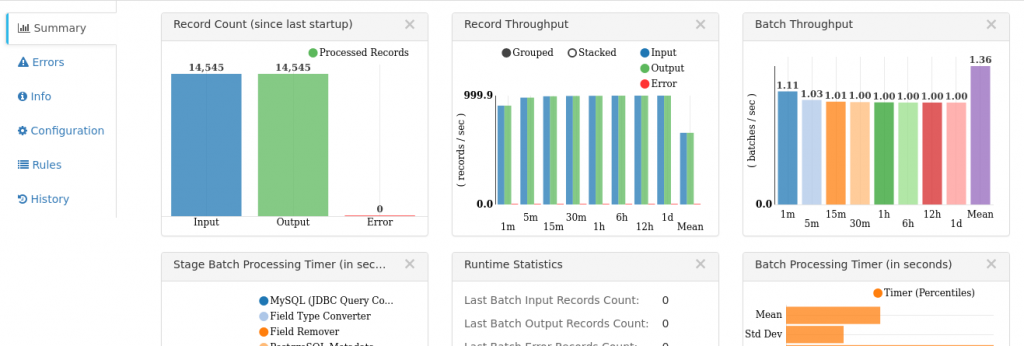
Once we are done setting up the pipeline, there is an option to validate the pipeline and fix if there is any error. Once everything looks good, we can start the pipeline and let it run to continuously watch the source table and populate the destination table, until it is stopped. While running, we also get a very nice dashboard, where we can see how many rows have been successfully processed and if there was any error in any of the stages. The pipeline only took a few seconds to move 14,545 rows.
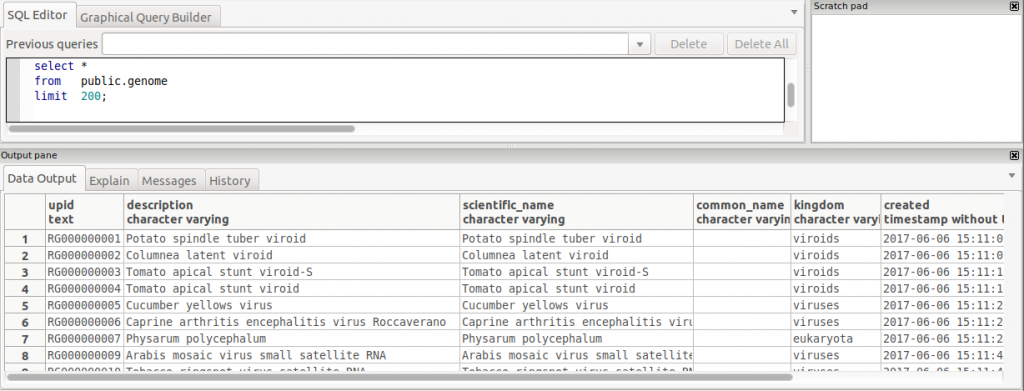
We can also check the results from the destination PostgreSQL database, where we can see it properly created all the columns with correct data types, even converted MySQL datetime field to PostgreSQL timestamp without timezone without any issue.
Final Thoughts
Considering the number of built-in connectors, the detailed documentation and fairly easy to use blocks, the initial impression of StreamSets has been quite positive. It also has a paid support option if someone is interested. I have plans to try it for more complex connectors and pipelines and will update here if I come across something interesting.
Thanks for reading.
Be First to Comment